Développer des applications événementielles avec Kafka et Docker
Avec l'essor des microservices, les architectures événementielles sont devenues de plus en plus populaires. Apache Kafka, une plateforme de streaming d'événements distribuée, est souvent au cœur de ces architectures. Malheureusement, la mise en place et le déploiement de votre propre instance Kafka pour le développement sont souvent délicats. Heureusement, Docker et les conteneurs facilitent grandement cette tâche.
Dans ce guide, vous apprendrez à :
- Utiliser Docker pour lancer un cluster Kafka
- Connecter une application non conteneurisée au cluster
- Connecter une application conteneurisée au cluster
- Déployer Kafka-UI pour aider au dépannage et au débogage
Prérequis
Les prérequis suivants sont nécessaires pour suivre ce guide pratique :
- Docker Desktop
- Node.js et yarn
- Connaissance de base de Kafka et Docker
Lancement de Kafka
Depuis Kafka 3.3, le déploiement de Kafka a été grandement simplifié en ne nécessitant plus Zookeeper grâce à KRaft (Kafka Raft). Avec KRaft, la mise en place d'une instance Kafka pour le développement local est beaucoup plus facile. À partir du lancement de Kafka 3.8, une nouvelle image Docker kafka-native est maintenant disponible, offrant un démarrage nettement plus rapide et une empreinte mémoire plus faible.
TipCe guide utilisera l'image apache/kafka, car elle inclut de nombreux scripts utiles pour gérer et travailler avec Kafka. Cependant, vous pouvez vouloir utiliser l'image apache/kafka-native, car elle démarre plus rapidement et nécessite moins de ressources.
Démarrage de Kafka
Démarrez un cluster Kafka de base en suivant les étapes suivantes. Cet exemple lancera un cluster, exposant le port 9092 sur l'hôte pour permettre à une application native de s'y connecter.
-
Démarrez un conteneur Kafka en exécutant la commande suivante :
$ docker run -d --name=kafka -p 9092:9092 apache/kafka -
Une fois l'image tirée, vous aurez une instance Kafka opérationnelle en une seconde ou deux.
-
L'image apache/kafka est livrée avec plusieurs scripts utiles dans le répertoire
/opt/kafka/bin. Exécutez la commande suivante pour vérifier que le cluster est opérationnel et obtenir son ID de cluster :$ docker exec -ti kafka /opt/kafka/bin/kafka-cluster.sh cluster-id --bootstrap-server :9092Cela produira une sortie similaire à la suivante :
Cluster ID: 5L6g3nShT-eMCtK--X86sw -
Créez un sujet d'exemple et produisez (ou publiez) quelques messages en exécutant la commande suivante :
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demoAprès l'exécution, vous pouvez entrer un message par ligne. Par exemple, entrez quelques messages, un par ligne. Quelques exemples pourraient être :
Premier messageEt
Deuxième messageAppuyez sur
Entréepour envoyer le dernier message, puis appuyez sur ctrl+c lorsque vous avez terminé. Les messages seront publiés sur Kafka. -
Confirmez que les messages ont été publiés dans le cluster en consommant les messages :
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server :9092 --topic demo --from-beginningVous devriez alors voir vos messages dans la sortie :
Premier message Deuxième messageSi vous le souhaitez, vous pouvez ouvrir un autre terminal et publier plus de messages et les voir apparaître chez le consommateur.
Lorsque vous avez terminé, appuyez sur ctrl+c pour arrêter de consommer les messages.
Vous avez un cluster Kafka fonctionnant localement et avez validé que vous pouvez vous y connecter.
Connexion à Kafka depuis une application non conteneurisée
Maintenant que vous avez montré que vous pouvez vous connecter à l'instance Kafka depuis une ligne de commande, il est temps de se connecter au cluster depuis une application. Dans cet exemple, vous utiliserez un projet Node simple qui utilise la bibliothèque KafkaJS.
Comme le cluster fonctionne localement et est exposé sur le port 9092, l'application peut se connecter au cluster à localhost:9092 (puisqu'elle fonctionne nativement et non dans un conteneur pour le moment). Une fois connectée, cette application d'exemple consignera les messages qu'elle consomme du sujet demo. De plus, lorsqu'elle s'exécute en mode développement, elle créera également le sujet s'il n'est pas trouvé.
-
Si le cluster Kafka de l'étape précédente n'est pas en cours d'exécution, exécutez la commande suivante pour démarrer une instance Kafka :
$ docker run -d --name=kafka -p 9092:9092 apache/kafka -
Clonez le dépôt GitHub localement.
$ git clone https://github.com/dockersamples/kafka-development-node.git -
Naviguez dans le projet.
cd kafka-development-node/app -
Installez les dépendances en utilisant yarn.
$ yarn install -
Démarrez l'application en utilisant
yarn dev. Cela définira la variable d'environnementNODE_ENVsurdevelopmentet utiliseranodemonpour surveiller les changements de fichiers.$ yarn dev -
L'application étant maintenant en cours d'exécution, elle consignera les messages reçus dans la console. Dans un nouveau terminal, publiez quelques messages en utilisant la commande suivante :
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demoPuis envoyez un message au cluster :
Message de testN'oubliez pas d'appuyer sur
ctrl+clorsque vous avez terminé pour arrêter de produire des messages.
Connexion à Kafka depuis des conteneurs et des applications natives
Maintenant que vous avez une application se connectant à Kafka via son port exposé, il est temps d'explorer les changements nécessaires pour se connecter à Kafka depuis un autre conteneur. Pour ce faire, vous allez maintenant exécuter l'application à partir d'un conteneur au lieu de nativement.
Mais avant de faire cela, il est important de comprendre comment fonctionnent les écouteurs Kafka et comment ces écouteurs aident les clients à se connecter.
Comprendre les écouteurs Kafka
Lorsqu'un client se connecte à un cluster Kafka, il se connecte en fait à un "broker". Bien que les brokers aient de nombreux rôles, l'un d'eux est de prendre en charge l'équilibrage de charge des clients. Lorsqu'un client se connecte, le broker renvoie un ensemble d'URL de connexion que le client doit ensuite utiliser pour se connecter pour produire ou consommer des messages. Comment ces URL de connexion sont-elles configurées ?
Chaque instance Kafka a un ensemble d'écouteurs et d'écouteurs annoncés. Les "écouteurs" sont ce à quoi Kafka se lie et les "écouteurs annoncés" configurent la manière dont les clients doivent se connecter au cluster. Les URL de connexion qu'un client reçoit sont basées sur l'écouteur auquel un client se connecte.
Définir les écouteurs
Pour que cela ait du sens, voyons comment Kafka doit être configuré pour prendre en charge deux opportunités de connexion :
- Connexions hôtes (celles passant par le port mappé de l'hôte) - celles-ci devront se connecter en utilisant localhost
- Connexions Docker (celles provenant de l'intérieur des réseaux Docker) - celles-ci ne peuvent pas se connecter en utilisant localhost, mais l'alias de réseau (ou l'adresse DNS) du service Kafka
Comme il existe deux méthodes de connexion différentes pour les clients, deux écouteurs différents sont requis - HOST et DOCKER. L'écouteur HOST indiquera aux clients de se connecter en utilisant localhost:9092, tandis que l'écouteur DOCKER informera les clients de se connecter en utilisant kafka:9093. Notez que cela signifie que Kafka écoute sur les deux ports 9092 et 9093. Mais, seul l'écouteur hôte doit être exposé à l'hôte.
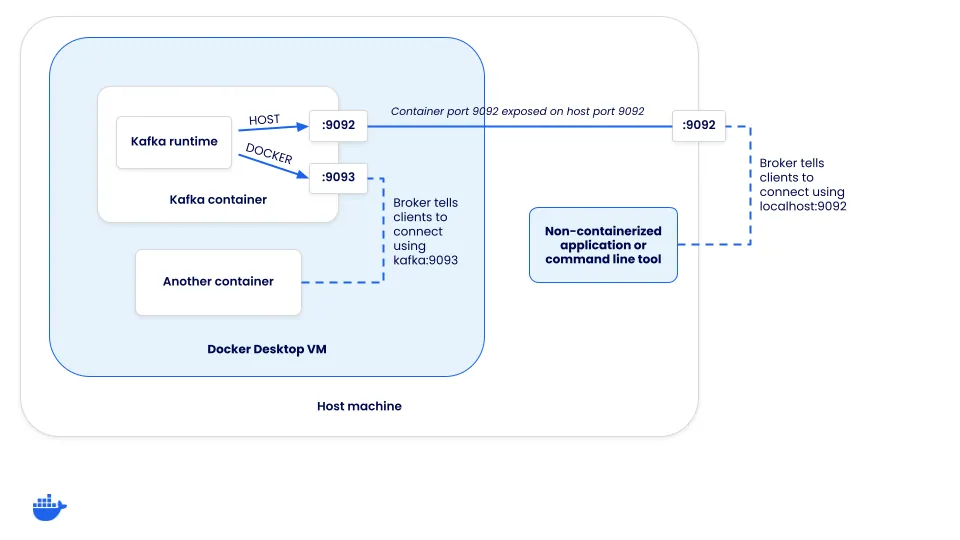
Afin de configurer cela, le compose.yaml pour Kafka nécessite une configuration supplémentaire. Une fois que vous commencez à outrepasser certaines des valeurs par défaut, vous devez également spécifier quelques autres options pour que le mode KRaft fonctionne.
services:
kafka:
image: apache/kafka-native
ports:
- "9092:9092"
environment:
# Configurer les écouteurs pour la communication docker et hôte
KAFKA_LISTENERS: CONTROLLER://localhost:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://localhost:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT
# Paramètres requis pour le mode KRaft
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091
# Écouteur à utiliser pour la communication de broker à broker
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
# Required for a single node cluster
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1Give it a try using the steps below.
-
If you have the Node app running from the previous step, go ahead and stop it by pressing
ctrl+cin the terminal. -
If you have the Kafka cluster running from the previous section, go ahead and stop that container using the following command:
$ docker rm -f kafka -
Start the Compose stack by running the following command at the root of the cloned project directory:
$ docker compose upAfter a moment, the application will be up and running.
-
In the stack is another service that can be used to publish messages. Open it by going to http://localhost:3000. As you type in a message and submit the form, you should see the log message of the message being received by the app.
This helps demonstrate how a containerized approach makes it easy to add additional services to help test and troubleshoot your application.
Adding cluster visualization
Once you start using containers in your development environment, you start to realize the ease of adding additional services that are solely focused on helping development, such as visualizers and other supporting services. Since you have Kafka running, it might be helpful to visualize what’s going on in the Kafka cluster. To do so, you can run the Kafbat UI web application.
To add it to your own project (it’s already in the demo application), you only need to add the following configuration to your Compose file:
services:
kafka-ui:
image: kafbat/kafka-ui:main
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: "true"
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093
depends_on:
- kafkaThen, once the Compose stack starts, you can open your browser to http://localhost:8080 and navigate around to view additional details about the cluster, check on consumers, publish test messages, and more.
Testing with Kafka
If you’re interested in learning how you can integrate Kafka easily into your integration tests, check out the Testing Spring Boot Kafka Listener using Testcontainers guide. This guide will teach you how to use Testcontainers to manage the lifecycle of Kafka containers in your tests.
Conclusion
By using Docker, you can simplify the process of developing and testing event-driven applications with Kafka. Containers simplify the process of setting up and deploying the various services you need to develop. And once they’re defined in Compose, everyone on the team can benefit from the ease of use.
In case you missed it earlier, all of the sample app code can be found at dockersamples/kafka-development-node.