Transcription et chat vidéo GenAI
Aperçu
Ce guide présente un projet de transcription et d'analyse vidéo utilisant un ensemble de technologies liées à la Pile GenAI.
Le projet met en avant les technologies suivantes :
- Docker et Docker Compose
- OpenAI
- Whisper
- Plongements
- Complétions de chat
- Pinecone
- Génération Augmentée par la Récupération
Remerciements
Ce guide est une contribution de la communauté. Docker souhaite remercier David Cardozo pour sa contribution à ce guide.
Prérequis
-
Vous disposez d'une clé API OpenAI.
NoteOpenAI est un service hébergé par un tiers et des frais peuvent s'appliquer.
-
Vous disposez d'une clé API Pinecone.
-
Vous avez installé la dernière version de Docker Desktop. Docker ajoute régulièrement de nouvelles fonctionnalités et certaines parties de ce guide peuvent ne fonctionner qu'avec la dernière version de Docker Desktop.
-
Vous disposez d'un client Git. Les exemples de cette section utilisent un client Git en ligne de commande, mais vous pouvez utiliser n'importe quel client.
À propos de l'application
L'application est un chatbot qui peut répondre à des questions à partir d'une vidéo. En outre, elle fournit des horodatages de la vidéo qui peuvent vous aider à trouver les sources utilisées pour répondre à votre question.
Obtenir et exécuter l'application
-
Clonez le dépôt de l'application exemple. Dans un terminal, exécutez la commande suivante.
$ git clone https://github.com/Davidnet/docker-genai.gitLe projet contient les répertoires et fichiers suivants :
├── docker-genai/ │ ├── docker-bot/ │ ├── yt-whisper/ │ ├── .env.example │ ├── .gitignore │ ├── LICENSE │ ├── README.md │ └── docker-compose.yaml -
Spécifiez vos clés API. Dans le répertoire
docker-genai, créez un fichier texte appelé.envet spécifiez vos clés API à l'intérieur. Voici le contenu du fichier.env.exampleque vous pouvez utiliser comme exemple.#---------------------------------------------------------------------------- # OpenAI #---------------------------------------------------------------------------- OPENAI_TOKEN=votre-cle-api # Remplacez votre-cle-api par votre clé API personnelle #---------------------------------------------------------------------------- # Pinecone #---------------------------------------------------------------------------- PINECONE_TOKEN=votre-cle-api # Remplacez votre-cle-api par votre clé API personnelle -
Construisez et exécutez l'application. Dans un terminal, placez-vous dans votre répertoire
docker-genaiet exécutez la commande suivante.$ docker compose up --buildDocker Compose construit et exécute l'application en fonction des services définis dans le fichier
docker-compose.yaml. Lorsque l'application est en cours d'exécution, vous verrez les journaux de 2 services dans le terminal.Dans les journaux, vous verrez que les services sont exposés sur les ports
8503et8504. Les deux services sont complémentaires.Le service
yt-whispers'exécute sur le port8503. Ce service alimente la base de données Pinecone avec les vidéos que vous souhaitez archiver dans votre base de connaissances. La section suivante explore ce service.
Utilisation du service yt-whisper
Le service yt-whisper est un service de traitement vidéo YouTube qui utilise le modèle OpenAI Whisper pour générer des transcriptions de vidéos et les stocker dans une base de données Pinecone. Les étapes suivantes montrent comment utiliser le service.
-
Ouvrez un navigateur et accédez au service yt-whisper à l'adresse http://localhost:8503.
-
Une fois l'application affichée, dans le champ URL Youtube, spécifiez une URL de vidéo Youtube et sélectionnez Soumettre. L'exemple suivant utilise https://www.youtube.com/watch?v=yaQZFhrW0fU.
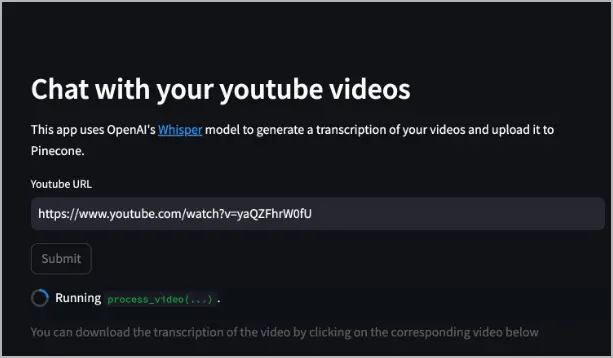
Le service yt-whisper télécharge l'audio de la vidéo, utilise Whisper pour le transcrire au format WebVTT (
*.vtt) (que vous pouvez télécharger), puis utilise le modèle text-embedding-3-small pour créer des plongements, et enfin télécharge ces plongements dans la base de données Pinecone.Après le traitement de la vidéo, une liste de vidéos apparaît dans l'application Web pour vous informer des vidéos qui ont été indexées dans Pinecone. Elle fournit également un bouton pour télécharger la transcription.
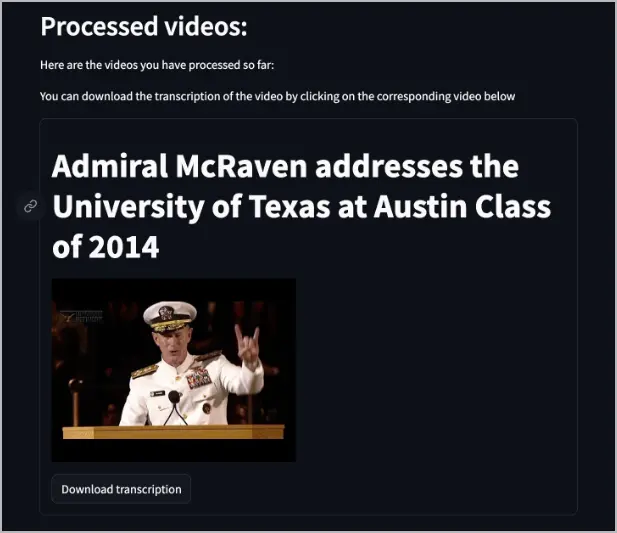
Vous pouvez maintenant accéder au service dockerbot sur le port
8504et poser des questions sur les vidéos.
Utilisation du service dockerbot
Le service dockerbot est un service de questions-réponses qui s'appuie à la fois sur la base de données Pinecone et sur un modèle d'IA pour fournir des réponses. Les étapes suivantes montrent comment utiliser le service.
NoteVous devez traiter au moins une vidéo via le service yt-whisper avant d'utiliser le service dockerbot.
-
Ouvrez un navigateur et accédez au service à http://localhost:8504.
-
Dans la zone de texte Que voulez-vous savoir sur vos vidéos ?, posez une question au Dockerbot sur une vidéo qui a été traitée par le service yt-whisper. L'exemple suivant pose la question : « Qu'est-ce qu'un biscuit au sucre ? ». La réponse à cette question se trouve dans la vidéo traitée dans l'exemple précédent, https://www.youtube.com/watch?v=yaQZFhrW0fU.
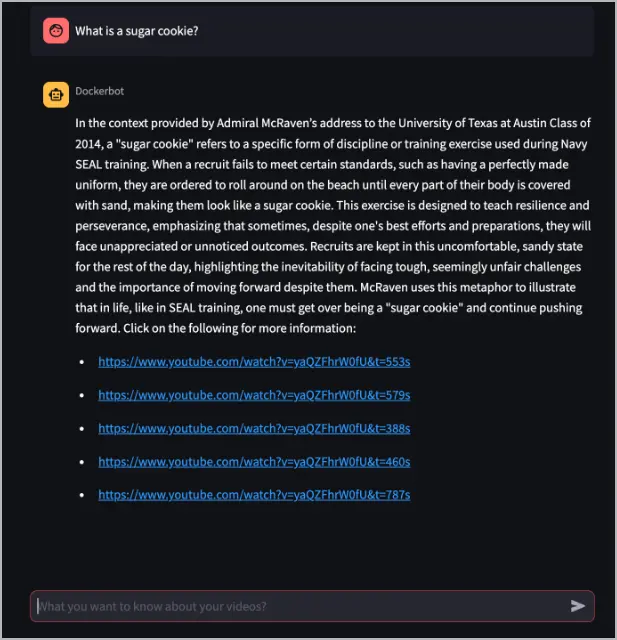
Dans cet exemple, le Dockerbot répond à la question et fournit des liens vers la vidéo avec des horodatages, qui peuvent contenir plus d'informations sur la réponse.
Le service dockerbot prend la question, la transforme en un plongement à l'aide du modèle text-embedding-3-small, interroge la base de données Pinecone pour trouver des plongements similaires, puis transmet ce contexte au gpt-4-turbo-preview pour générer une réponse.
-
Sélectionnez le premier lien pour voir quelles informations il fournit. En vous basant sur l'exemple précédent, sélectionnez https://www.youtube.com/watch?v=yaQZFhrW0fU&t=553s.
Dans le lien de l'exemple, vous pouvez voir que la section de la vidéo répond parfaitement à la question : « Qu'est-ce qu'un biscuit au sucre ? ».
Explorer l'architecture de l'application
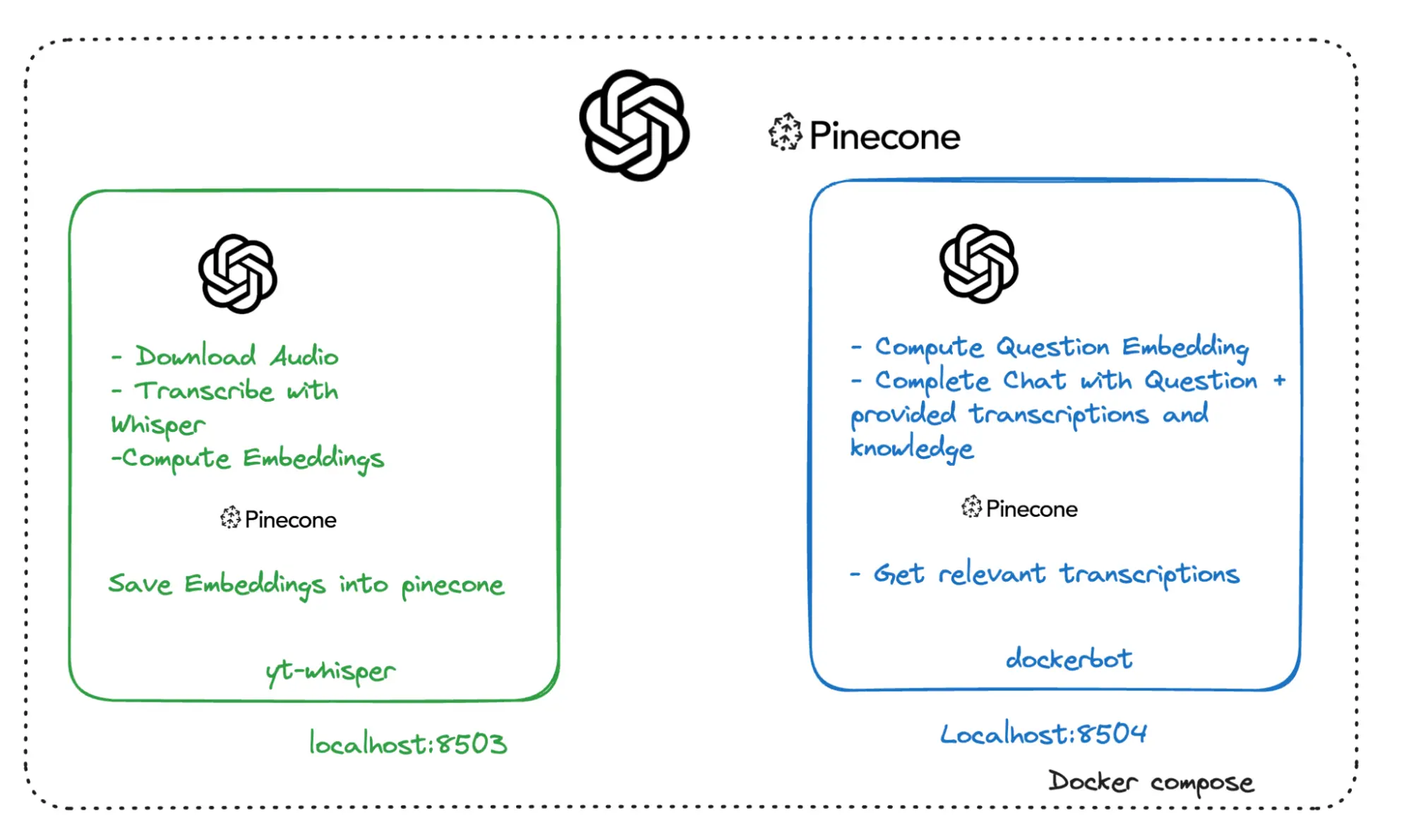
L'image suivante montre l'architecture de service de haut niveau de l'application, qui comprend :
- yt-whisper : Un service local, exécuté par Docker Compose, qui interagit avec les services distants OpenAI et Pinecone.
- dockerbot : Un service local, exécuté par Docker Compose, qui interagit avec les services distants OpenAI et Pinecone.
- OpenAI : Un service tiers distant.
- Pinecone : Un service tiers distant.
Explorer les technologies utilisées et leur rôle
Docker et Docker Compose
L'application utilise Docker pour s'exécuter dans des conteneurs, offrant un environnement cohérent et isolé pour son exécution. Cela signifie que l'application fonctionnera comme prévu dans ses conteneurs Docker, quelles que soient les différences du système sous-jacent. Pour en savoir plus sur Docker, consultez l' Aperçu de la prise en main.
Docker Compose est un outil pour définir et exécuter des applications multi-conteneurs.
Compose facilite l'exécution de cette application avec une seule commande, docker compose up. Pour plus de détails, consultez l'
Aperçu de Compose.
API OpenAI
L'API OpenAI fournit un service LLM connu pour ses technologies d'IA et d'apprentissage automatique de pointe. Dans cette application, la technologie d'OpenAI est utilisée pour générer des transcriptions à partir de l'audio (en utilisant le modèle Whisper) et pour créer des plongements pour les données textuelles, ainsi que pour générer des réponses aux requêtes des utilisateurs (en utilisant GPT et les complétions de chat). Pour plus de détails, consultez openai.com.
Whisper
Whisper est un système de reconnaissance vocale automatique développé par OpenAI, conçu pour transcrire le langage parlé en texte. Dans cette application, Whisper est utilisé pour transcrire l'audio des vidéos YouTube en texte, permettant un traitement et une analyse plus approfondis du contenu vidéo. Pour plus de détails, consultez Présentation de Whisper.
Plongements
Les plongements sont des représentations numériques de texte ou d'autres types de données, qui capturent leur signification d'une manière qui peut être traitée par des algorithmes d'apprentissage automatique. Dans cette application, les plongements sont utilisés pour convertir les transcriptions vidéo dans un format vectoriel qui peut être interrogé et analysé pour sa pertinence par rapport à l'entrée de l'utilisateur, facilitant ainsi la recherche et la génération de réponses efficaces dans l'application. Pour plus de détails, consultez la documentation sur les Plongements d'OpenAI.
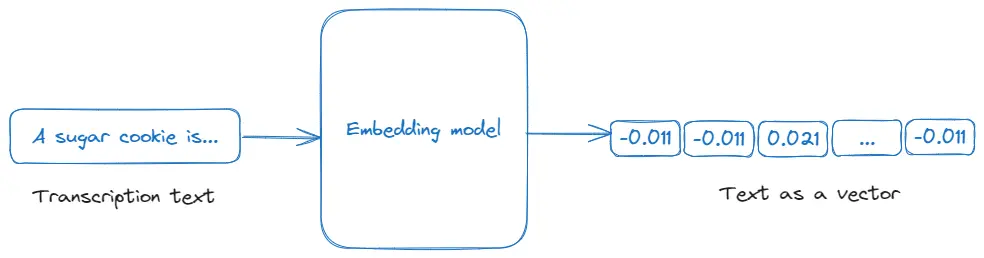
Complétions de chat
La complétion de chat, telle qu'utilisée dans cette application via l'API d'OpenAI, fait référence à la génération de réponses conversationnelles basées sur un contexte ou une invite donné. Dans l'application, elle est utilisée pour fournir des réponses intelligentes et contextuelles aux requêtes des utilisateurs en traitant et en intégrant des informations provenant des transcriptions vidéo et d'autres entrées, améliorant ainsi les capacités interactives du chatbot. Pour plus de détails, consultez la documentation de l'API de complétions de chat d'OpenAI.
Pinecone
Pinecone est un service de base de données vectorielle optimisé pour la recherche de similarités, utilisé pour créer et déployer des applications de recherche vectorielle à grande échelle. Dans cette application, Pinecone est utilisé pour stocker et récupérer les plongements des transcriptions vidéo, permettant une fonctionnalité de recherche efficace et pertinente dans l'application en fonction des requêtes des utilisateurs. Pour plus de détails, consultez pincone.io.
Génération Augmentée par la Récupération
La Génération Augmentée par la Récupération (RAG) est une technique qui combine la récupération d'informations avec un modèle de langage pour générer des réponses basées sur des documents ou des données récupérés. Dans le RAG, le système récupère des informations pertinentes (dans ce cas, via des plongements de transcriptions vidéo) puis utilise un modèle de langage pour générer des réponses basées sur ces données récupérées. Pour plus de détails, consultez le livre de recettes d'OpenAI pour Réponses aux questions génératives augmentées par la récupération avec Pinecone.
Prochaines étapes
Explorez comment créer une application de bot PDF en utilisant l'IA générative, ou consultez plus d'exemples GenAI dans le dépôt Pile GenAI.