Pilote de réseau IPvlan
Le pilote IPvlan donne aux utilisateurs un contrôle total sur l'adressage IPv4 et IPv6. Le pilote VLAN se base sur cela en donnant aux opérateurs un contrôle complet du balisage VLAN de couche 2 et même du routage IPvlan L3 pour les utilisateurs intéressés par l'intégration du réseau underlay. Pour les déploiements overlay qui abstraient les contraintes physiques, voir le pilote overlay multi-hôte.
IPvlan est une nouvelle approche de la technique éprouvée de virtualisation réseau. Les implémentations Linux sont extrêmement légères car plutôt que d'utiliser le bridge Linux traditionnel pour l'isolation, elles sont associées à une interface Ethernet Linux ou sous-interface pour imposer la séparation entre les réseaux et la connectivité au réseau physique.
IPvlan offre un certain nombre de fonctionnalités uniques et beaucoup de place pour d'autres innovations avec les différents modes. Deux avantages de haut niveau de ces approches sont les implications positives sur les performances en contournant le bridge Linux et la simplicité d'avoir moins de pièces mobiles. Retirer le bridge qui réside traditionnellement entre la NIC de l'hôte Docker et l'interface de conteneur laisse une configuration simple constituée d'interfaces de conteneur, attachées directement à l'interface de l'hôte Docker. Ce résultat est facile d'accès pour les services externes car il n'y a pas besoin de mappage de ports dans ces scénarios.
Options
Le tableau suivant décrit les options spécifiques au pilote que vous pouvez passer à
--opt lors de la création d'un réseau utilisant le pilote ipvlan.
| Option | Défaut | Description |
|---|---|---|
ipvlan_mode |
l2 |
Définit le mode de fonctionnement IPvlan. Peut être l'un des : l2, l3, l3s |
ipvlan_flag |
bridge |
Définit le drapeau de mode IPvlan. Peut être l'un des : bridge, private, vepa |
parent |
Spécifie l'interface parent à utiliser. |
Exemples
Prérequis
- Les exemples de cette page sont tous à hôte unique.
- Tous les exemples peuvent être exécutés sur un seul hôte exécutant Docker. Tout
exemple utilisant une sous-interface comme
eth0.10peut être remplacé pareth0ou toute autre interface parent valide sur l'hôte Docker. Les sous-interfaces avec un.sont créées à la volée. Les interfaces-o parentpeuvent aussi être omises entièrement de ladocker network createet le pilote créera une interfacedummyqui activera la connectivité hôte local pour exécuter les exemples. - Exigences du noyau :
- IPvlan noyau Linux v4.2+ (le support pour les noyaux antérieurs existe mais est bogué). Pour vérifier votre version actuelle du noyau, utilisez
uname -r
- IPvlan noyau Linux v4.2+ (le support pour les noyaux antérieurs existe mais est bogué). Pour vérifier votre version actuelle du noyau, utilisez
Exemple d'utilisation du mode IPvlan L2
Un exemple de la topologie du mode IPvlan L2 est montré dans l'image suivante.
Le pilote est spécifié avec l'option -d driver_name. Dans ce cas -d ipvlan.
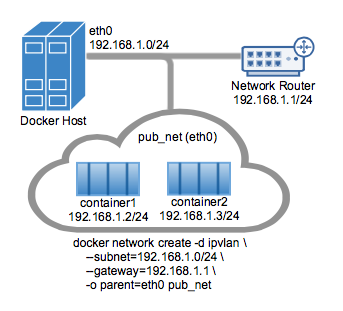
L'interface parent dans l'exemple suivant -o parent=eth0 est configurée comme suit :
$ ip addr show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.1.250/24 brd 192.168.1.255 scope global eth0
Utilisez le réseau de l'interface de l'hôte comme --subnet dans la
docker network create. Le conteneur sera attaché au même réseau que
l'interface hôte comme défini via l'option -o parent=.
Créez le réseau IPvlan et exécutez un conteneur en s'y attachant :
# IPvlan (-o ipvlan_mode= Par défaut en mode L2 si non spécifié)
$ docker network create -d ipvlan \
--subnet=192.168.1.0/24 \
--gateway=192.168.1.1 \
-o ipvlan_mode=l2 \
-o parent=eth0 db_net
# Démarrer un conteneur sur le réseau db_net
$ docker run --net=db_net -it --rm alpine /bin/sh
# NOTE: les conteneurs ne peuvent PAS pinguer les interfaces hôte sous-jacentes car
# elles sont intentionnellement filtrées par Linux pour une isolation supplémentaire.
Le mode par défaut pour IPvlan est l2. Si -o ipvlan_mode= est laissé non spécifié,
le mode par défaut sera utilisé. De même, si le --gateway est laissé vide, la
première adresse utilisable sur le réseau sera définie comme passerelle. Par exemple, si
le sous-réseau fourni dans la création de réseau est --subnet=192.168.1.0/24 alors la
passerelle que le conteneur reçoit est 192.168.1.1.
Pour aider à comprendre comment ce mode interagit avec d'autres hôtes, la figure suivante montre le même segment de couche 2 entre deux hôtes Docker qui s'applique au mode IPvlan L2.
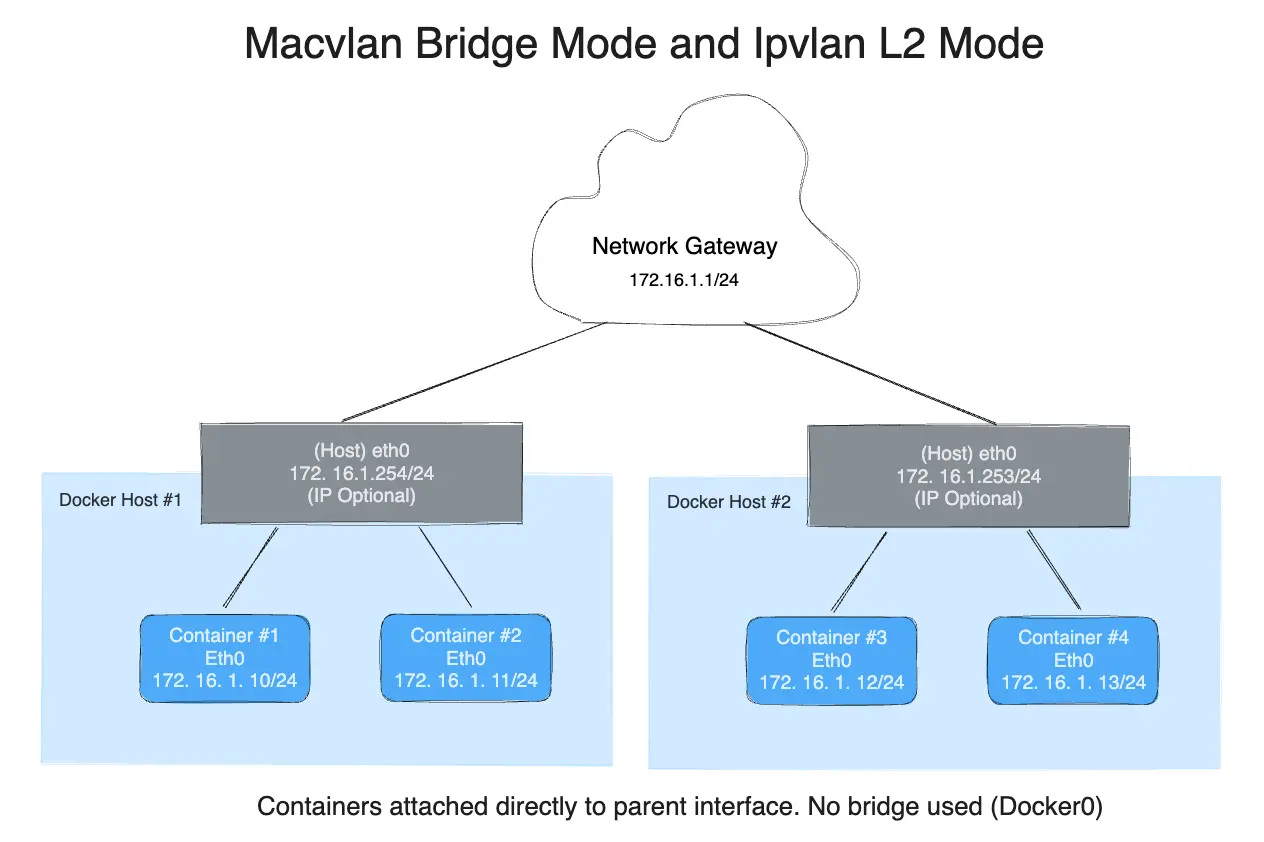
Le suivant créera exactement le même réseau que le réseau db_net créé
plus tôt, avec les valeurs par défaut du pilote pour --gateway=192.168.1.1 et -o ipvlan_mode=l2.
# IPvlan (-o ipvlan_mode= Par défaut en mode L2 si non spécifié)
$ docker network create -d ipvlan \
--subnet=192.168.1.0/24 \
-o parent=eth0 db_net_ipv
# Démarrer un conteneur avec un nom explicite en mode démon
$ docker run --net=db_net_ipv --name=ipv1 -itd alpine /bin/sh
# Démarrer un second conteneur et pinguer en utilisant le nom du conteneur
# pour voir la fonctionnalité de résolution de nom incluse dans docker
$ docker run --net=db_net_ipv --name=ipv2 -it --rm alpine /bin/sh
$ ping -c 4 ipv1
# NOTE: les conteneurs ne peuvent PAS pinguer les interfaces hôte sous-jacentes car
# elles sont intentionnellement filtrées par Linux pour une isolation supplémentaire.
Les pilotes prennent aussi en charge le drapeau --internal qui isolera complètement
les conteneurs sur un réseau de toute communication externe à ce réseau. Puisque
l'isolation réseau est étroitement couplée à l'interface parent du réseau, le résultat
de laisser l'option -o parent= hors d'une docker network create est exactement
le même que l'option --internal. Si l'interface parent n'est pas spécifiée ou si le
drapeau --internal est utilisé, une interface parent de type netlink dummy est créée
pour l'utilisateur et utilisée comme interface parent isolant efficacement le réseau
complètement.
Les deux exemples suivants docker network create aboutissent à des réseaux identiques
auxquels vous pouvez attacher des conteneurs :
# `-o parent=` vide crée un réseau isolé
$ docker network create -d ipvlan \
--subnet=192.168.10.0/24 isolated1
# Le drapeau explicite '--internal' est le même :
$ docker network create -d ipvlan \
--subnet=192.168.11.0/24 --internal isolated2
# Même le '--subnet=' peut être laissé vide et le sous-réseau
# IPAM par défaut de 172.18.0.0/16 sera assigné
$ docker network create -d ipvlan isolated3
$ docker run --net=isolated1 --name=cid1 -it --rm alpine /bin/sh
$ docker run --net=isolated2 --name=cid2 -it --rm alpine /bin/sh
$ docker run --net=isolated3 --name=cid3 -it --rm alpine /bin/sh
# Pour s'attacher à n'importe lequel utilisez `docker exec` et démarrez un shell
$ docker exec -it cid1 /bin/sh
$ docker exec -it cid2 /bin/sh
$ docker exec -it cid3 /bin/sh
Exemple d'utilisation du mode trunk L2 802.1Q IPvlan
Architecturalement, le mode trunk L2 IPvlan est le même que Macvlan en ce qui concerne les passerelles et l'isolation de chemin L2. Il y a des nuances qui peuvent être avantageuses pour la pression de table CAM dans les commutateurs ToR, une MAC par port et l'épuisement MAC sur la NIC parent d'un hôte pour en nommer quelques-unes. Le scénario de trunk 802.1Q ressemble au même. Les deux modes adhèrent aux standards de balisage et ont une intégration transparente avec le réseau physique pour l'intégration underlay et les intégrations de plugin de fournisseur matériel.
Les hôtes sur le même VLAN sont typiquement sur le même sous-réseau et presque toujours sont groupés ensemble basé sur leur politique de sécurité. Dans la plupart des scénarios, une application multi-niveaux est hiérarchisée en différents sous-réseaux car le profil de sécurité de chaque processus nécessite une forme d'isolation. Par exemple, héberger votre traitement de carte de crédit sur le même réseau virtuel que le serveur web frontal serait un problème de conformité réglementaire, en plus de contourner la bonne pratique établie de longue date des architectures de défense en profondeur en couches. Les VLANs ou l'équivalent VNI (Virtual Network Identifier) lors de l'utilisation du pilote Overlay, sont la première étape dans l'isolation du trafic locataire.
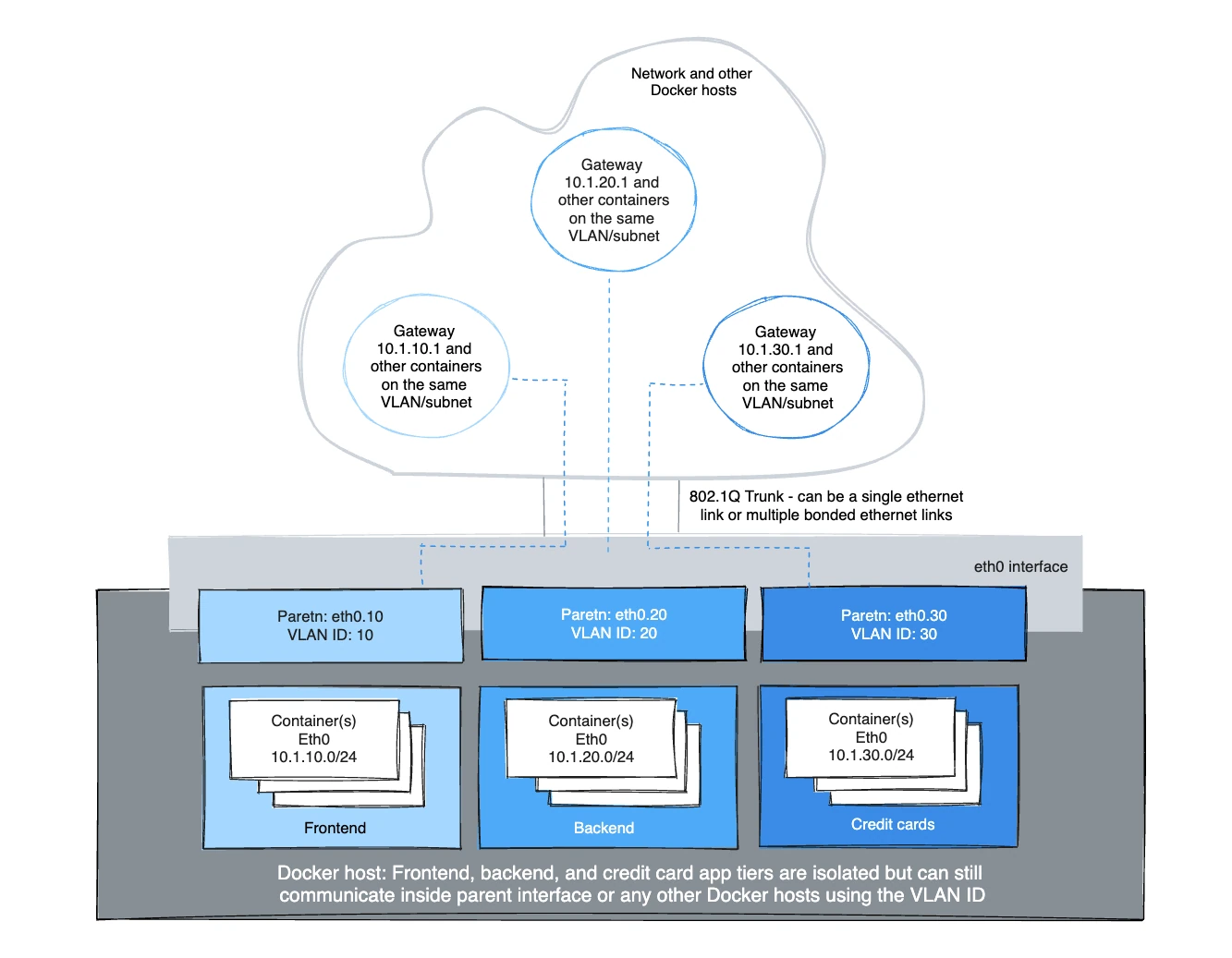
La sous-interface Linux balisée avec un VLAN peut soit déjà exister ou sera
créée quand vous appelez une docker network create. docker network rm supprimera
la sous-interface. Les interfaces parent telles que eth0 ne sont pas supprimées, seules
les sous-interfaces avec un index parent netlink > 0.
Pour que le pilote ajoute/supprime les sous-interfaces VLAN, le format doit être
interface_name.vlan_tag. D'autres noms de sous-interface peuvent être utilisés comme
parent spécifié, mais le lien ne sera pas supprimé automatiquement quand
docker network rm est invoqué.
L'option d'utiliser soit des sous-interfaces VLAN parent existantes ou laisser Docker les gérer
permet à l'utilisateur soit de gérer complètement les interfaces Linux et
la mise en réseau ou laisser Docker créer et supprimer les sous-interfaces VLAN parent
(netlink ip link) sans effort de l'utilisateur.
Par exemple : utilisez eth0.10 pour désigner une sous-interface de eth0 balisée avec l'id
VLAN de 10. La commande ip link équivalente serait
ip link add link eth0 name eth0.10 type vlan id 10.
L'exemple crée les réseaux balisés VLAN et démarre ensuite deux conteneurs pour tester la connectivité entre conteneurs. Différents VLANs ne peuvent se pinguer l'un l'autre sans un routeur routant entre les deux réseaux. L'espace de noms par défaut n'est pas atteignable par conception IPvlan afin d'isoler les espaces de noms de conteneur de l'hôte sous-jacent.
VLAN ID 20
Dans le premier réseau balisé et isolé par l'hôte Docker, eth0.20 est l'interface
parent balisée avec l'id VLAN 20 spécifié avec -o parent=eth0.20.
D'autres formats de nommage peuvent être utilisés, mais les liens doivent être ajoutés et supprimés
manuellement en utilisant ip link ou les fichiers de configuration Linux. Tant que le -o parent
existe, tout peut être utilisé s'il est conforme au netlink Linux.
# maintenant ajoutez des réseaux et hôtes comme vous le feriez normalement en s'attachant à l'interface maître (sous)interface qui est balisée
$ docker network create -d ipvlan \
--subnet=192.168.20.0/24 \
--gateway=192.168.20.1 \
-o parent=eth0.20 ipvlan20
# dans deux terminaux séparés, démarrez un conteneur Docker et les conteneurs peuvent maintenant se pinguer.
$ docker run --net=ipvlan20 -it --name ivlan_test1 --rm alpine /bin/sh
$ docker run --net=ipvlan20 -it --name ivlan_test2 --rm alpine /bin/sh
VLAN ID 30
Dans le second réseau, balisé et isolé par l'hôte Docker, eth0.30 est l'interface
parent balisée avec l'id VLAN 30 spécifié avec -o parent=eth0.30. Le
ipvlan_mode= par défaut en mode l2 ipvlan_mode=l2. Il peut aussi être explicitement
défini avec le même résultat comme montré dans l'exemple suivant.
# maintenant ajoutez des réseaux et hôtes comme vous le feriez normalement en s'attachant à l'interface maître (sous)interface qui est balisée.
$ docker network create -d ipvlan \
--subnet=192.168.30.0/24 \
--gateway=192.168.30.1 \
-o parent=eth0.30 \
-o ipvlan_mode=l2 ipvlan30
# dans deux terminaux séparés, démarrez un conteneur Docker et les conteneurs peuvent maintenant se pinguer.
$ docker run --net=ipvlan30 -it --name ivlan_test3 --rm alpine /bin/sh
$ docker run --net=ipvlan30 -it --name ivlan_test4 --rm alpine /bin/sh
La passerelle est définie à l'intérieur du conteneur comme passerelle par défaut. Cette passerelle serait typiquement un routeur externe sur le réseau.
$$ ip route
default via 192.168.30.1 dev eth0
192.168.30.0/24 dev eth0 src 192.168.30.2
Exemple : Mode IPvlan L2 Multi-Sous-réseau démarrant deux conteneurs sur le même sous-réseau
et se pinguant l'un l'autre. Pour que le 192.168.114.0/24 atteigne
192.168.116.0/24 il nécessite un routeur externe en mode L2. Le mode L3 peut router
entre sous-réseaux qui partagent un -o parent= commun.
Les adresses secondaires sur les routeurs réseau sont communes car un espace d'adresse devient épuisé pour ajouter un autre secondaire à une interface VLAN L3 ou communément appelée "interface virtuelle commutée" (SVI).
$ docker network create -d ipvlan \
--subnet=192.168.114.0/24 --subnet=192.168.116.0/24 \
--gateway=192.168.114.254 --gateway=192.168.116.254 \
-o parent=eth0.114 \
-o ipvlan_mode=l2 ipvlan114
$ docker run --net=ipvlan114 --ip=192.168.114.10 -it --rm alpine /bin/sh
$ docker run --net=ipvlan114 --ip=192.168.114.11 -it --rm alpine /bin/sh
Un point clé à retenir est que les opérateurs ont la capacité de mapper leur réseau physique dans
leur réseau virtuel pour intégrer les conteneurs dans leur environnement sans
révisions opérationnelles nécessaires. NetOps dépose un trunk 802.1Q dans
l'hôte Docker. Ce lien virtuel serait le -o parent= passé dans la création de réseau.
Pour les liens non balisés (non-VLAN), c'est aussi simple que -o parent=eth0 ou
pour les trunks 802.1Q avec des IDs VLAN chaque réseau est mappé au VLAN/Sous-réseau correspondant
depuis le réseau.
Un exemple étant, NetOps fournit l'ID VLAN et les sous-réseaux associés pour les VLANs
étant passés sur le lien Ethernet vers le serveur hôte Docker. Ces valeurs sont
branchées dans les commandes docker network create lors du provisionnement des
réseaux Docker. Ce sont des configurations persistantes qui sont appliquées chaque fois
que le moteur Docker démarre ce qui évite d'avoir à gérer souvent des fichiers de configuration
complexes. Les interfaces réseau peuvent aussi être gérées manuellement en
étant pré-créées et la mise en réseau Docker ne les modifiera jamais, et les utilisera
comme interfaces parent. Exemples de mappages de NetOps vers les commandes de réseau Docker
sont comme suit :
- VLAN: 10, Sous-réseau: 172.16.80.0/24, Passerelle: 172.16.80.1
--subnet=172.16.80.0/24 --gateway=172.16.80.1 -o parent=eth0.10
- VLAN: 20, Sous-réseau IP: 172.16.50.0/22, Passerelle: 172.16.50.1
--subnet=172.16.50.0/22 --gateway=172.16.50.1 -o parent=eth0.20
- VLAN: 30, Sous-réseau: 10.1.100.0/16, Passerelle: 10.1.100.1
--subnet=10.1.100.0/16 --gateway=10.1.100.1 -o parent=eth0.30
Exemple du mode IPvlan L3
IPvlan nécessitera que les routes soient distribuées à chaque point de terminaison. Le pilote construit seulement le port mode IPvlan L3 et attache le conteneur à l'interface. La distribution de route à travers un cluster est au-delà de l'implémentation initiale de ce pilote à portée d'hôte unique. En mode L3, l'hôte Docker est très similaire à un routeur démarrant de nouveaux réseaux dans le conteneur. Ils sont sur des réseaux que le réseau upstream ne connaîtra pas sans distribution de route. Pour ceux curieux de comment IPvlan L3 s'intégrera dans la mise en réseau de conteneur, voir les exemples suivants.
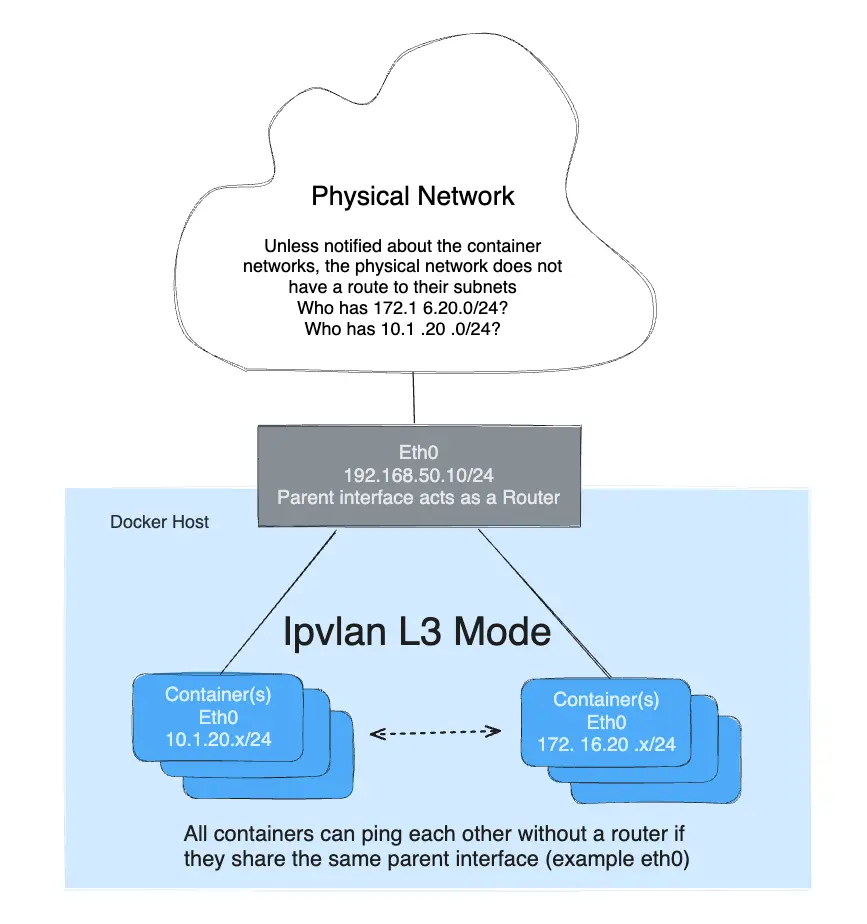
Le mode IPvlan L3 supprime tout le trafic broadcast et multicast. Cette raison seule fait du mode IPvlan L3 un candidat de choix pour ceux cherchant une échelle massive et des intégrations réseau prévisibles. Il est prévisible et mènera en retour à de plus grands temps de fonctionnement car il n'y a pas de bridging impliqué. Les boucles de bridging ont été responsables de pannes de haut profil qui peuvent être difficiles à localiser selon la taille du domaine de défaillance. Ceci est dû à la nature en cascade des BPDUs (Bridge Port Data Units) qui sont inondés à travers un domaine broadcast (VLAN) pour trouver et bloquer les boucles de topologie. Éliminer les domaines de bridging, ou au moins, les garder isolés à une paire de ToRs (commutateurs top of rack) réduira les instabilités de bridging difficiles à dépanner. Le mode IPvlan L2 est bien adapté pour des VLANs isolés seulement trunkés dans une paire de ToRs qui peuvent fournir un fabric sans boucle et non-bloquant. L'étape suivante est de router au bord via le mode IPvlan L3 qui réduit un domaine de défaillance à un hôte local seulement.
- Le mode L3 doit être sur un sous-réseau séparé comme l'espace de noms par défaut puisqu'il nécessite une route netlink dans l'espace de noms par défaut pointant vers l'interface parent IPvlan.
- L'interface parent utilisée dans cet exemple est
eth0et elle est sur le sous-réseau192.168.1.0/24. Remarquez que ledocker networkn'est pas sur le même sous-réseau queeth0. - Contrairement aux modes IPvlan l2, différents sous-réseaux/réseaux peuvent se pinguer l'un l'autre tant
qu'ils partagent la même interface parent
-o parent=.
$$ ip a show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:50:56:39:45:2e brd ff:ff:ff:ff:ff:ff
inet 192.168.1.250/24 brd 192.168.1.255 scope global eth0
- Une passerelle traditionnelle ne signifie pas grand-chose pour une interface IPvlan mode L3 puisque
il n'y a pas de trafic broadcast autorisé. À cause de cela, la passerelle par défaut du conteneur
pointe vers le dispositif
eth0des conteneurs. Voir ci-dessous pour la sortie CLI deip routeouip -6 routedepuis l'intérieur d'un conteneur L3 pour les détails.
Le mode -o ipvlan_mode=l3 doit être explicitement spécifié puisque le mode
IPvlan par défaut est l2.
L'exemple suivant ne spécifie pas d'interface parent. Les pilotes réseau créeront un lien de type dummy pour l'utilisateur plutôt que de rejeter la création de réseau et d'isoler les conteneurs pour qu'ils ne communiquent qu'entre eux.
# Créer le réseau IPvlan L3
$ docker network create -d ipvlan \
--subnet=192.168.214.0/24 \
--subnet=10.1.214.0/24 \
-o ipvlan_mode=l3 ipnet210
# Tester la connectivité 192.168.214.0/24
$ docker run --net=ipnet210 --ip=192.168.214.10 -itd alpine /bin/sh
$ docker run --net=ipnet210 --ip=10.1.214.10 -itd alpine /bin/sh
# Tester la connectivité L3 de 10.1.214.0/24 vers 192.168.214.0/24
$ docker run --net=ipnet210 --ip=192.168.214.9 -it --rm alpine ping -c 2 10.1.214.10
# Tester la connectivité L3 de 192.168.214.0/24 vers 10.1.214.0/24
$ docker run --net=ipnet210 --ip=10.1.214.9 -it --rm alpine ping -c 2 192.168.214.10
NoteRemarquez qu'il n'y a pas d'option
--gateway=dans la création de réseau. Le champ est ignoré si un est spécifié en model3. Jetez un coup d'œil à la table de routage du conteneur depuis l'intérieur du conteneur :# À l'intérieur d'un conteneur mode L3 $$ ip route default dev eth0 192.168.214.0/24 dev eth0 src 192.168.214.10
Pour pinguer les conteneurs depuis un hôte Docker distant ou que le conteneur puisse pinguer un hôte distant, l'hôte distant ou le réseau physique entre doivent avoir une route pointant vers l'adresse IP hôte de l'interface eth de l'hôte Docker du conteneur.
Mode IPvlan L2 dual stack IPv4 IPv6
-
Non seulement Libnetwork vous donne un contrôle complet sur l'adressage IPv4, mais il vous donne aussi un contrôle total sur l'adressage IPv6 ainsi qu'une parité de fonctionnalités entre les deux familles d'adresses.
-
L'exemple suivant commencera avec IPv6 seulement. Démarrez deux conteneurs sur le même VLAN
139et pinguez-vous l'un l'autre. Puisque le sous-réseau IPv4 n'est pas spécifié, l' IPAM par défaut provisionnera un sous-réseau IPv4 par défaut. Ce sous-réseau est isolé sauf si le réseau upstream le route explicitement sur VLAN139.
# Créer un réseau v6
$ docker network create -d ipvlan \
--ipv6 --subnet=2001:db8:abc2::/64 --gateway=2001:db8:abc2::22 \
-o parent=eth0.139 v6ipvlan139
# Démarrer un conteneur sur le réseau
$ docker run --net=v6ipvlan139 -it --rm alpine /bin/sh
Voir l'interface eth0 du conteneur et la table de routage v6 :
# À l'intérieur du conteneur IPv6
$$ ip a show eth0
75: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc2::1/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc2::/64 dev eth0 proto kernel metric 256
default via 2001:db8:abc2::22 dev eth0 metric 1024
Démarrez un second conteneur et pinguez l'adresse v6 du premier conteneur.
# Tester la connectivité L2 sur IPv6
$ docker run --net=v6ipvlan139 -it --rm alpine /bin/sh
# À l'intérieur du second conteneur IPv6
$$ ip a show eth0
75: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
inet6 2001:db8:abc2::2/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ping6 2001:db8:abc2::1
PING 2001:db8:abc2::1 (2001:db8:abc2::1): 56 data bytes
64 bytes from 2001:db8:abc2::1%eth0: icmp_seq=0 ttl=64 time=0.044 ms
64 bytes from 2001:db8:abc2::1%eth0: icmp_seq=1 ttl=64 time=0.058 ms
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.044/0.051/0.058/0.000 ms
L'exemple suivant configurera un réseau dual stack IPv4/IPv6 avec un exemple
VLAN ID de 140.
Ensuite créez un réseau avec deux sous-réseaux IPv4 et un sous-réseau IPv6, tous ayant des passerelles explicites :
$ docker network create -d ipvlan \
--subnet=192.168.140.0/24 --subnet=192.168.142.0/24 \
--gateway=192.168.140.1 --gateway=192.168.142.1 \
--subnet=2001:db8:abc9::/64 --gateway=2001:db8:abc9::22 \
-o parent=eth0.140 \
-o ipvlan_mode=l2 ipvlan140
Démarrez un conteneur et voir eth0 et les tables de routage v4 & v6 :
$ docker run --net=ipvlan140 --ip6=2001:db8:abc2::51 -it --rm alpine /bin/sh
$ ip a show eth0
78: eth0@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.140.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc9::1/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ip route
default via 192.168.140.1 dev eth0
192.168.140.0/24 dev eth0 proto kernel scope link src 192.168.140.2
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc9::/64 dev eth0 proto kernel metric 256
default via 2001:db8:abc9::22 dev eth0 metric 1024
Démarrez un second conteneur avec une adresse --ip4 spécifique et pinguez le premier hôte
en utilisant des paquets IPv4 :
$ docker run --net=ipvlan140 --ip=192.168.140.10 -it --rm alpine /bin/sh
NoteDifférents sous-réseaux sur la même interface parent en mode IPvlan
L2ne peuvent se pinguer l'un l'autre. Cela nécessite un routeur pour proxy-arp les requêtes avec un sous-réseau secondaire. Cependant, IPvlanL3routera le trafic unicast entre sous-réseaux disparates tant qu'ils partagent le même lien parent-o parent.
Mode IPvlan L3 dual stack IPv4 IPv6
Exemple : Mode IPvlan L3 Dual Stack IPv4/IPv6, Multi-Sous-réseau w/ Tag VLAN 802.1Q:118
Comme dans tous les exemples, une interface VLAN balisée n'a pas à être utilisée. Les
sous-interfaces peuvent être échangées avec eth0, eth1, bond0 ou toute autre interface valide
sur l'hôte autre que l'interface de bouclage lo.
La différence principale que vous verrez est que le mode L3 ne crée pas de route par défaut
avec un next-hop mais plutôt définit une route par défaut pointant vers dev eth seulement
puisque ARP/Broadcasts/Multicast sont tous filtrés par Linux selon la conception. Puisque
l'interface parent agit essentiellement comme un routeur, l'IP de l'interface parent
et le sous-réseau doivent être différents des réseaux de conteneur. C'est l'opposé
des modes bridge et L2, qui doivent être sur le même sous-réseau (domaine broadcast)
afin de transférer les paquets broadcast et multicast.
# Créer un réseau IPvlan L3 Dual Stack IPv6+IPv4
# Les passerelles pour v4 et v6 sont définies sur un dev e.g. 'default dev eth0'
$ docker network create -d ipvlan \
--subnet=192.168.110.0/24 \
--subnet=192.168.112.0/24 \
--subnet=2001:db8:abc6::/64 \
-o parent=eth0 \
-o ipvlan_mode=l3 ipnet110
# Démarrer quelques conteneurs sur le réseau (ipnet110)
# dans des terminaux séparés et vérifier la connectivité
$ docker run --net=ipnet110 -it --rm alpine /bin/sh
# Démarrer un second conteneur spécifiant l'adresse v6
$ docker run --net=ipnet110 --ip6=2001:db8:abc6::10 -it --rm alpine /bin/sh
# Démarrer un troisième spécifiant l'adresse IPv4
$ docker run --net=ipnet110 --ip=192.168.112.30 -it --rm alpine /bin/sh
# Démarrer un 4ème spécifiant les adresses IPv4 et IPv6
$ docker run --net=ipnet110 --ip6=2001:db8:abc6::50 --ip=192.168.112.50 -it --rm alpine /bin/sh
Les sorties de l'interface et de la table de routage sont comme suit :
$$ ip a show eth0
63: eth0@if59: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.112.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc6::10/64 scope link nodad
valid_lft forever preferred_lft forever
# Notez que la route par défaut est le dispositif eth car les ARPs sont filtrés.
$$ ip route
default dev eth0 scope link
192.168.112.0/24 dev eth0 proto kernel scope link src 192.168.112.2
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc6::/64 dev eth0 proto kernel metric 256
default dev eth0 metric 1024
NoteIl peut y avoir un bug lors de la spécification d'adresses
--ip6=quand vous supprimez un conteneur avec une adresse v6 spécifiée et démarrez ensuite un nouveau conteneur avec la même adresse v6 il lève ce qui suit comme si l'adresse n'était pas proprement libérée dans le pool v6. Il échouera à démonter le conteneur et sera laissé mort.
docker: Error response from daemon: Address already in use.
Créer manuellement des liens 802.1Q
VLAN ID 40
Si un utilisateur ne veut pas que le pilote crée la sous-interface VLAN, elle doit
exister avant d'exécuter docker network create. Si vous avez un nommage de sous-interface
qui n'est pas interface.vlan_id il est honoré dans l'option -o parent=
encore une fois tant que l'interface existe et est up.
Les liens, quand créés manuellement, peuvent être nommés n'importe comment tant qu'ils existent quand
le réseau est créé. Les liens créés manuellement ne sont pas supprimés peu importe
le nom quand le réseau est supprimé avec docker network rm.
# créer une nouvelle sous-interface liée au vlan dot1q 40
$ ip link add link eth0 name eth0.40 type vlan id 40
# activer la nouvelle sous-interface
$ ip link set eth0.40 up
# maintenant ajouter des réseaux et hôtes comme vous le feriez normalement en s'attachant à la (sous)interface maître qui est balisée
$ docker network create -d ipvlan \
--subnet=192.168.40.0/24 \
--gateway=192.168.40.1 \
-o parent=eth0.40 ipvlan40
# dans deux terminaux séparés, démarrez un conteneur Docker et les conteneurs peuvent maintenant se pinguer.
$ docker run --net=ipvlan40 -it --name ivlan_test5 --rm alpine /bin/sh
$ docker run --net=ipvlan40 -it --name ivlan_test6 --rm alpine /bin/sh
Exemple : Sous-interface VLAN créée manuellement avec n'importe quel nom :
# créer une nouvelle sous interface liée au vlan dot1q 40
$ ip link add link eth0 name foo type vlan id 40
# activer la nouvelle sous-interface
$ ip link set foo up
# maintenant ajouter des réseaux et hôtes comme vous le feriez normalement en s'attachant à la (sous)interface maître qui est balisée
$ docker network create -d ipvlan \
--subnet=192.168.40.0/24 --gateway=192.168.40.1 \
-o parent=foo ipvlan40
# dans deux terminaux séparés, démarrez un conteneur Docker et les conteneurs peuvent maintenant se pinguer.
$ docker run --net=ipvlan40 -it --name ivlan_test5 --rm alpine /bin/sh
$ docker run --net=ipvlan40 -it --name ivlan_test6 --rm alpine /bin/sh
Les liens créés manuellement peuvent être nettoyés avec :
$ ip link del foo
Comme avec tous les pilotes Libnetwork, ils peuvent être mélangés et assortis, même jusqu'à exécuter des pilotes d'écosystème tiers en parallèle pour une flexibilité maximale pour l'utilisateur Docker.